In This week’s lab session we looked at how Text Encoding has been used to enrich the content of two different websites – Artist’s Books Online and the Old Bailey Online.
Both of these projects make use of Text Encoding Initiative standard to mark-up the the content of their websites. HTML, as we have seen before, is a basic mark-up language which defines the layout and appearance of a text. TEI guidelines make use of XML, and define the semantic content of a text, making use of an extensive set of descriptive tags. The purpose of this to make texts more searchable, by allowing computers to make relationships between texts, and parts of a text. By marking up a text, it is transformed from a list of words into something which a computer can interpret and analyse, using the rules laid out by TEI. For example, in a play, the parts of text referring to characters and dialogue can be annotated, and using RDF triples, the relationships between these linked – which character says what to another character.
The legally allowed categories by which the elements and attributes of an XML document can be annotated is defined by the DTD (Document Type Definition). The DTD for Artists’ Books Online is available to view, and it lays out all the possible elements and attributes of the books which must be described – some are compulsory, others are optional. There is a sample of how this translates into the XML mark-up for a particular book, but there is no option to view the XML for each artists’ book in the collection, the XML is simply in the background of the website.
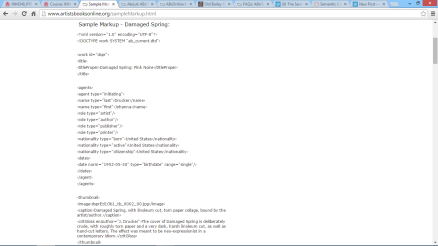
Comparison of the XML and HTML views of “Damaged Spring”

With Old Bailey Online, it is much easier to access the XML version of each document – there is a button at the bottom of each trial record to switch from HTML to XML. Old Bailey Online doesn’t make its DTD explicitly available, though they do state which catagories of information hav been marked up in the XML:
- * Crime (divided into 9 general categories and 56 specific types)
- Crime date
- Crime location
- Defendant name
- Defendant status or occupational label
- * Defendant gender
- Alias names used by the defendant and the victim
- Defendant location
- Victim name
- Victim status or occupational label
- * Victim gender
- Judges’ names
- Jury names
- Other person names (see below)
- * Verdicts (divided into 4 general categories and 23 specific types)
- * Punishments (divided into 6 general categories and 26 specific types)
- * Defendant’s age (only regularly provided for convicts from 1789)
- Advertisements
* Tagged fields labelled by an asterisk can be tabulated statistically.


Comparison of HTML and XML views
What I find interesting about the difference between the two is how the mark-up is applied to the documents in both websites.
Artists’ Books Online have openly published their DTD, as the books submitted are manually annotated, whereas the trial proceedings on Old Bailey Online were marked up using a combination of automated and manual mark-up methods. For example, the 1674-1834 trials were run through an automated mark-up program GATE (developed by the University of Sheffield), to detect names within the text and was able to identify approximately 80-90%. Automated methods clearly represent huge savings in time, especially for a corpus as large as the Old Bailey trials, but they still have to be supplemented by very labour-intensive manual checking.
As the project website states, marking-up a text is not a neutral activity, but “represents the imposition of a modern layer of interpretation onto these texts, reflecting the historical understanding of project staff in the early twenty-first century”. As with any digital technology, the human decisions behind the scenes will impact on the outcome for a user, and as information specialists we must always try to understand how these may affect the results we are seeing – whether from searching a historical database, or a Google.